
1.1 正则表达式
| 字符 | 作用 |
|---|---|
| ^ 尖角号 | 表示匹配以尖角号后面的单词开头的行 |
| $ 美元符 | 表示匹配以美元符后面的单词结尾的行 |
| ^$ 组合符 | 表示空行 |
| . 点号 | 匹配任意一个且只有一个字符 |
| \ 转义字符 | 让有特殊含义的字符输出自身 |
| * 星号 | 重复前一个字符(连续出现)0次或N次 |
| .* 组合符 | 匹配所有内容 |
| ^.* 组合符 | 匹配任意多个字符开头的内容 |
| .*$ 组合符 | 匹配任意多个字符结尾的内容 |
| [abc] | 匹配[]集合内的任意一个字符 |
| [^abc] | 匹配不包含^后的任意字符 |
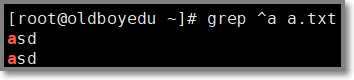
1.1.1 ^ 尖角号 表示匹配以尖角号后面的单词开头的行
# grep "^a" a.txt
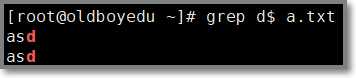
1.1.2 $ 美元符 表示匹配以美元符后面的单词结尾的行
# grep "d$" a.txt
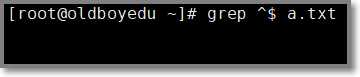
1.1.3 ^$ 组合符 表示空行
# grep "^$" a.txt
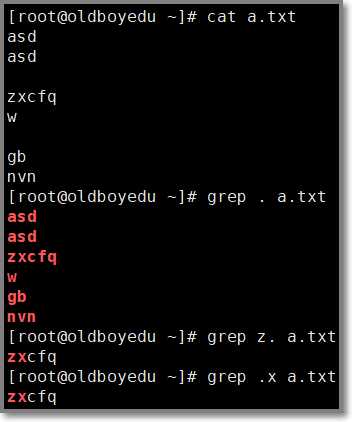
1.1.4 . 点号 匹配任意一个且只有一个字符
# 匹配所有字符(不包括空行)
grep . a.txt
# 匹配z和z后一个字符
grep "z." a.txt
# 匹配x和x前一个字符
grep ".x" a.txt
1.1.5 \ 转义字符 让有特殊含义的字符输出自身
# grep "\^" a

1.1.6 * 星号 重复前一个字符(连续出现)0次或N次
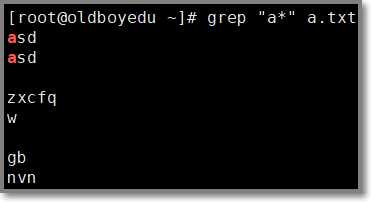
# grep "a*" a.txt
1.1.7 .* 组合符 匹配所有内容
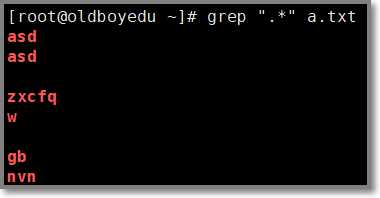
# grep ".*" a.txt
1.1.8 ^.* 组合符 匹配任意多个字符开头的内容
# grep "^.*zx" a.txt

1.1.9 .*$ 组合符 匹配任意多个字符结尾的内容
# grep "fq.*$" a.txt

1.1.10 [abc] 匹配[]集合内的任意一个字符
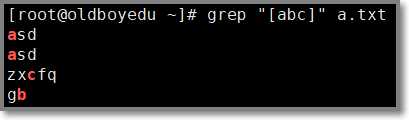
# grep "[abc]" a.txt
1.1.11 [^abc] 匹配不包含^后的任意字符
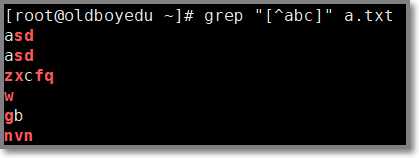
# grep "[^abc]" a.txt
1.2 扩展正则
| 字符 | 作用 |
|---|---|
| + 加号 | 匹配前一个字符1次或多次 |
| ? 问号 | 匹配前一个字符0次或1次 |
| | 管道 | 表示用或的方式找出数个字符串 |
| () 括号 | 分组过滤被括起来的东西表示一个整体 |
| \n | 引用前面\(\)的内容 n为数字 |
| [:/]+ | 匹配括号内的:或/字符1次或多次 |
| a{n,m} | 匹配前一个字符最少n次,最多m次 |
| a{n,} | 匹配前一个字符最少n次 |
| a{n} | 匹配前一个字符正好n次 |
| a{,m} | 匹配前一个字符最多m次 |
1.2.1 + 加号 匹配前一个字符1次或多次
# egrep "wr+y" b.txt

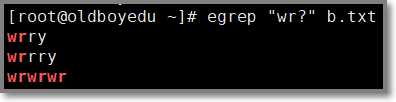
1.2.2 ? 问号 匹配前一个字符0次或1次
# egrep "wr?" b.txt
1.2.3 |管道 表示用或的方式找出数个字符串
# egrep "gd|good" b.txt

1.2.4 () 括号 分组过滤被括起来的东西表示一个整体
# egrep "g(la|oo)d" b.txt

1.2.5 \n 引用前面()的内容 n为数字
# sed -n 's/g\(oo\)d/b\1d/p' b.txt

1.2.6 [:/]+ 匹配括号内的:或/字符1次或多次
# egrep "[:/]+" b.txt

1.2.7 a{n,m} 匹配前一个字符最少n次,最多m次
# egrep "a{5,6}" c.txt

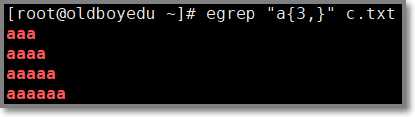
1.2.8 a{n,} 匹配前一个字符最少n次
# egrep "a{3,}" c.txt
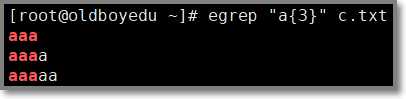
1.2.9 a{n} 匹配前一个字符正好n次
# egrep "a{3}" c.txt
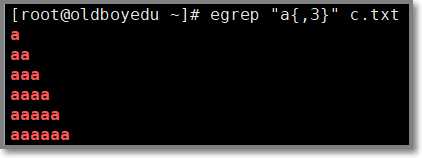
1.2.10 a{,m} 匹配前一个字符最多m次
# egrep "a{,3}" c.txt
本文链接:https://www.yunweibase.com/archives/665
网友评论comments